Twitterアカウントの交流をPythonでネットワーク可視化する【Tweepy・NetworkX・Pyvis】
Twitterで特定界隈の交流をPythonでネットワーク可視化するコードを作りました。
例として、ジャンプに関係する公式アカウントの交流マップを作成しました。同じ手順で任意の界隈の関係性を可視化できます。コードも載せているのでPythonの基礎知識があれば再現できます。
背景・モチベーション
Twitterアカウントの関係性といえばフォロー/フォロワー(FF)関係が代表的です。しかし、FF関係は各アカウントに1000件以上存在することも珍しくなく、複数アカウントのFF関係を取得しようとすると、情報量が膨大になりネットワーク可視化には不向きです。
今回は、RTやリプライといった「交流」に注目しました。
直近のRTやリプライをもとに関係性を構築することで、情報量を抑えるとともに関係性の質を高めています。
Twitterアカウントの交流を可視化する既存のツールにはwhotwi仲良しマップがあります。
whotwi仲良しマップは非常に便利なサービスですが、片側からのRTだけでも交流していると判定される仕様のため、個人アカウントと公式アカウントが交流しているといった直感とは反する結果が得られます。
そこで、相互にリツイートやリプライをしてる場合にのみ関係性を示すマップを自作することにしました。
方法
PythonのtweepyというライブラリでTwitterAPIを使用しています。実行環境はGoogle Colaboratryです。
ネットワーク作成にはNetworkX、ネットワーク可視化用にはPyvisを使用しています。
今回は例として、ジャンプ作家や編集者のアカウントの交流ネットワークを可視化しました。
大まかな流れは以下の通り。
1. ジャンプ編集部・ジャンプ+がフォローしているアカウント一覧を取得
2. 各アカウントの直近のリツイート・リプライ履歴を取得
3. 相互にリツイート・リプライしているアカウントを「交流している」と判定
4. 交流のあるアカウントを連結したネットワーク図を作成
具体的なコードは後述。
完成イメージ
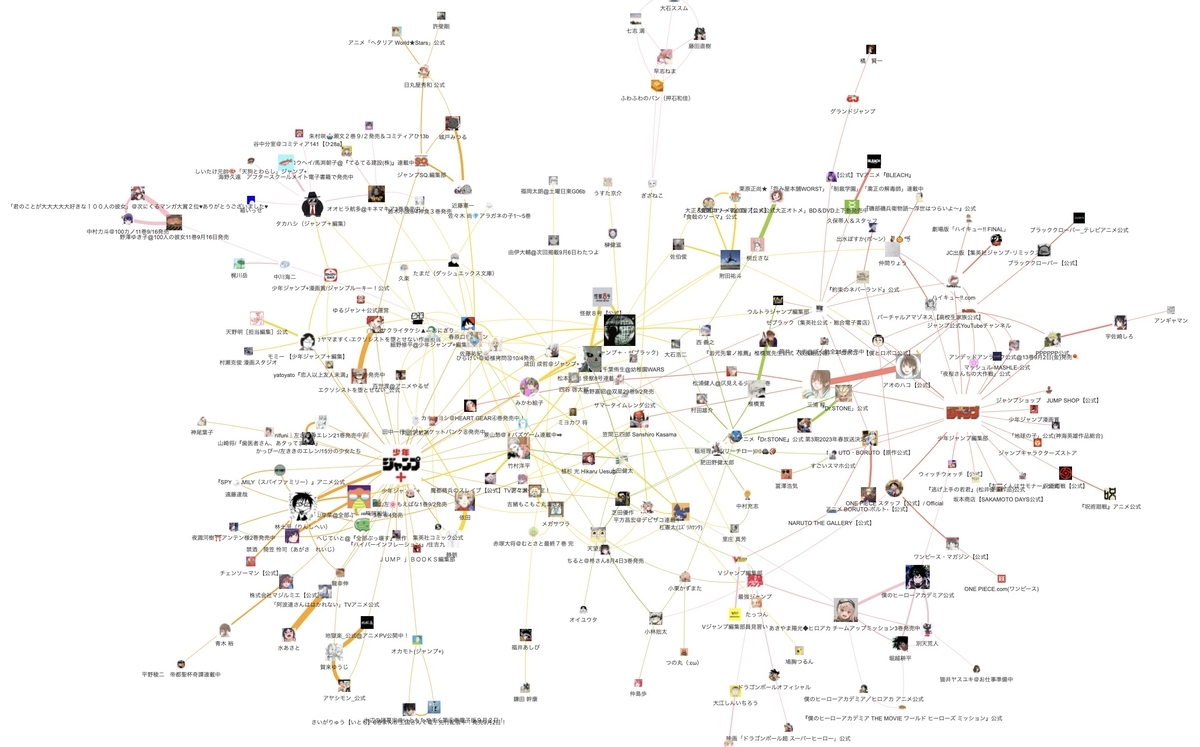
リンク先で拡大・縮小できます。
https://shima-ui.github.io/MangaAnimeNetwork/
編集部・編集者のアカウントが複数の作品を繋げるハブ的な役割を果たしていることや、公式アカウントとその作者の交流が活発な様子を確認できます。
また、ジャンプ本誌と比べてジャンプ+では作家同士の交流が活発な様子も確認できます。
コード
コピペで再現可能です。コメントアウトで簡単な説明はしていますが、ちゃんと知りたい方は参考URL先を参照して頂ければと思います。
Python初心者が作成しているため、コードが汚いのはご愛嬌ということで。
必要ライブラリのインストールと下準備
ライブラリのインストールやAPIの設定を行います。APIのconsumer keyなどは各自で取得したものを使ってください。
#tweepy !pip install git+https://github.com/tweepy/tweepy.git import tweepy #進捗報告 !pip install tqdm import tqdm #カウント import collections #データ処理 import pandas as pd #ネットワーク import networkx as nx from networkx.algorithms import community import itertools #ネットワーク可視化 !pip install pyvis from pyvis.network import Network # 自分のAPI情報を記入 consumer_key = "" consumer_secret = "" access_token = "" access_token_secret = "" bearer_token = "" # OAuth認証 auth = tweepy.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) # APIのインスタンスを生成 api = tweepy.API(auth, wait_on_rate_limit=True) #データフレーム作成用の列名リスト col_names_st=["source","target"] col_names_stw=["source","target","weight"]
ノードの作成
今回は指定アカウントがフォローしているアカウントを対象としましたが、リストからアカウント一覧を取得したり、指定アカウントがRTしているアカウントを対象にしたり、色々とやり方はあると思います。
#ネットワークの起点とするアカウントのリスト sources = ["@jump_henshubu", "@shonenjump_plus"] #起点アカウントがフォローしているアカウント一覧を作成 nodelist = [] #アイコン画像やユーザー名を対応させるための辞書 image_dict = {} name_dict = {} for source in sources: for status in tweepy.Cursor(api.get_friends, screen_name = source , count=200).items(1000): nodelist.append(status.screen_name) image_dict[status.screen_name] = status.profile_image_url name_dict[status.screen_name] = status.name nodelist = set(nodelist)
各ノードと交流しているアカウントを取得
先に全てのノードのエッジ候補を取得・保存しておくことで、エッジを確定する際の処理量を減らしています。
#エッジの候補を保存しておくデータフレーム df_check = pd.DataFrame(columns=col_names_st) for node in tqdm.tqdm(nodelist): node_mentions = [] try: for status in api.user_timeline(screen_name=node, count=200): node_mention = status.entities['user_mentions'] try: node_mentions.append(node_mention[0]['screen_name']) except Exception as e: pass except Exception as e: pass #交流回数を記録しておいてエッジの重みに使います node_mentions_dict = collections.Counter(node_mentions) date_add = [node,node_mentions_dict] df_add = pd.DataFrame([date_add], columns=col_names_st) df_check = pd.concat([df_check, df_add])
エッジ候補のうち対象ノード間を繋ぐものだけを確定
#描画するエッジを保存するデータフレーム df_all = pd.DataFrame(columns=col_names_stw) for node in tqdm.tqdm(nodelist): group1_dict = df_check[df_check['source']==node]['target'].iloc[-1] for key1,value1 in group1_dict.items(): if key1 in nodelist: group2_dict = df_check[df_check['source']==key1]['target'].iloc[-1] for key2,value2 in group2_dict.items(): if key2 == node: score = min([value1,value2]) if score > 0: date_add = [node,key1,score] df_add = pd.DataFrame([date_add], columns=col_names_stw) df_all = pd.concat([df_all, df_add]) #エッジに重みと長さを設定 df_all['value']=df_all['weight'] df_all['length']=(1/df_all['weight']*50)
ネットワークを作成
#データフレームからネットワークを作成 G = nx.convert_matrix.from_pandas_edgelist(df_all, edge_attr=True) #自己ループを削除 G.remove_edges_from(nx.selfloop_edges(G)) #エッジを持たないノードを削除 G_rem=[] for v in G: G_deg=G.degree(v) #print("G_deg[",v,"]=",G_deg) if G_deg==0: #print("v=",v) G_rem.append(v) G.remove_nodes_from(G_rem) #中心性(Pagerank)を計算 pr = nx.pagerank(G) #グラフ描画用にprの値を調節 mn = min(list(pr.values())) mx = max(list(pr.values())) for key, val in pr.items(): pr[key] = (1+((val-mn)/(mx-mn))*4)
ノードに属性を追加
#クラスタリング k = 8 #クラスタ数 comp = community.girvan_newman(G) community_list = [] for communities in itertools.islice(comp, k-1): community_list.append(tuple(sorted(c) for c in communities)) community_list = list(community_list[k-2]) #ノード属性を指定するためのデータフレーム(名前・ラベル・サイズ・形・画像URL・色) df_nodes = pd.DataFrame(columns=['name','label','size','shape','image','color']) for node in G: if node in community_list[0]: c = 'orange' elif node in community_list[1]: c = 'gold' elif node in community_list[2]: c = 'pink' elif node in community_list[3]: c = 'salmon' elif node in community_list[4]: c = 'yellowgreen' elif node in community_list[5]: c = 'sandybrown' elif node in community_list[6]: c = 'violet' else: c = 'pink' #ノード属性を追加 date_add = [node,name_dict[node],pr[node]*10,"image",image_dict[node],c] df_add = pd.DataFrame([date_add], columns=['name','label','size','shape','image','color']) df_nodes = pd.concat([df_nodes, df_add]) #ノード属性をネットワークに反映 nodes_attr = df_nodes.set_index('name').to_dict(orient = 'index') nx.set_node_attributes(G, nodes_attr)
ネットワーク可視化
# networkxグラフをpyvisグラフに変換 g = Network(width="100%", height="100%") #画面サイズに対する比率を設定 g.from_nx(G) #NetworkXのグラフをPyvisに変換 # グラフをhtmlで出力 g.show_buttons() g.show("network.html")